XML Processing using the Whitebeam Environment
How XML data is processed.Before you can understand the XML tree structure in Whitebeam you need to understand a little about how the Presentation Engine puts pages together. Page generation is a two stage process:
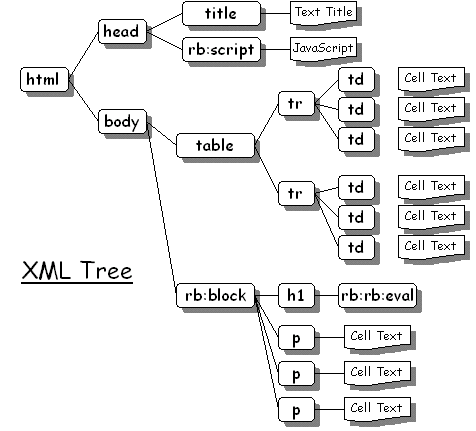
Stage 1: Buiding the XML Tree.Stage one builds the tree. The resulting tree is represented in the following diagram: This generates an internal representation of the tree. This is done internally for the main Presentation Page, and is performed manually by calling XmlParser.build Each of the nodes within the tree has some associated behaviour that has yet to be executed, this behaviour is determined by the name of the tag. (Generally the behaviour of a tag when it is executed is to generate its output representation that will be sent to the browser. How it does this is down to that specific tag). Stage 2: Executing the XML Tree.Each element in the XML tree (XML tag, text, comment etc) has an 'output' area associated with it. In general the intention is for each element to set its output area to be the text it wants to send to the client. For example for a simple text element the default behaviour is to set the text element's output area to be the same as the text it contains. In order to get the elements to populate their output areas the tree (or a sub-part of the tree) must be executed. The Presentation Engine does this for each Presentation Page - taking the root of the tree and getting it to execute itself. For trees constructed using the JavaScript API you can manually execute a portion of the tree by invoking the 'execute' method. Separating the tree build from executing the XML allows a branch of the tree to be executed more than once if necessary - potentially creating different output each time. This is how things like the rb:repeatfor tag is executed - the block of XML withing the rb:repeatfor tag is executed a number of times with loop variables changing each time. Whether or not the text gets eventually output depends on what the node'sparent wants to do. This behaviour is either defined 1) as default behaviour by the Whitebeam system or 2) the default behaviour can be overridden by the developer by using the <rb:macrotag> facility or 3) a user defined tag can have its behaviour specified by the developer by using the <rb:macrotag> facility or - finally - 4) by explicitly manipulating the XML tree using the JavaScript API. A simple HTML tag like the paragraph marker <p> will generate its output by executing each of its children and then concatenating the output from each of those into its own output area. Consider the following example:
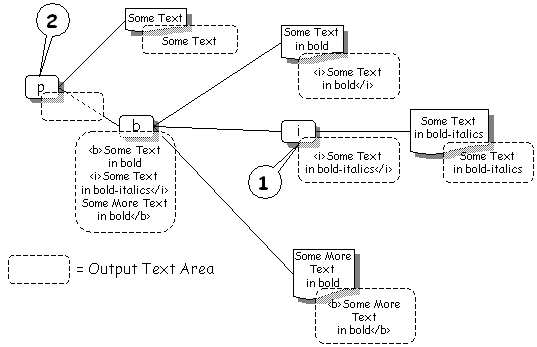
The paragraph tag is in the process of being processed. It's behaviour is to execute each of its children. The child XML tags in this example are all standard XHTML mark-up. The behaviour of these tags it to recursively process their children then concatenate their output along with their own wrapper. Conside the <i> tag (marked [1] in the diagram). This has executed its child - a simple text element. The output area of the text element has been set to the contents of the text field : "Some Text in bold-italics". The <i> tag then sets it's output area to be the concatenation of all it's children - wrapped in <i> and </i>. This happens all the way up the tree. The diagram illustrates the contents of the output areas for each XML element after all the children of the paragraph [2] have been executed but before the paragraph has generated its own output. You can see that to generate the contents of its own text area the paragraph element simply concatenates the contents of its own direct children - wrapping them in a <p> and </p> . |