

Postgres Replication
SubjectThis article covers how we adapted the Postgres dbmirror replication system to work in a high-performance Whitebeam installation - and the changes we had to make! Postgres has been an integral part of a whitebeam installation since its open source debut back in June 2001. Postgres provides the high performance data storage and access underlying the whole Whitebeam architecture. Until now though we've had one major sticking point - database replication. The IBM DB2 version of our templates have been running for a number of years on a replicated database environment, but the cost of DB2 is prohibitive and we've found the performance of Postgres to very little different from DB2. We want to migrate everything over to Postgres! With version 0.9.35, we've bitten the bullet and solved the replication issue. YellowHawk and Redbourne are now running Whitebeam datacentres using replicated Postgres databases. The biggest stumbling block has been our use of large objects in the Whitebeam schema used to stored files. None of the open-source replication schemes we looked at could cope with large objects. In Version 0.9.35 we've re-written the file template to use BYTEA data for file storage, openning up the way for replication. Replication modelFigure 1 shows the basic desired model. In a resiliant configuration the active Presentation Engines talk to a master Postgres database. Some 'process' (replication) is then responsible for copying all database changes from the master to a secondary slave server. 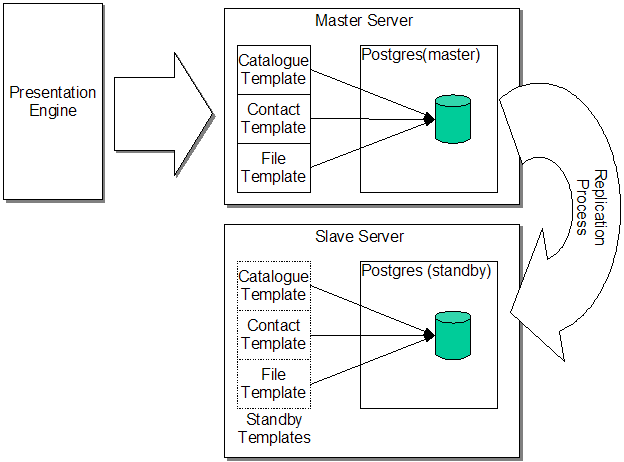 Figure 1 : Basic replication model There are a number of different replication schemes available. In keeping with Whitebeams open-source model we wanted to make use of an open source solution. Our first choice was to be Slony-I. This system seems to have been gaining press recently as a Master to Multiple Slave replication system. Unfortunately we couldn't get Slony to work - the configuration scripts continually insisted that our database wasn't suitable because of the lack of primary keys on certain tables (all the tables have primary keys - so no idea what it was complaining about).. The Slony-I documentation was also quite difficult to find at the time, and didn't seem to provide answers to the questions we had. I would point out that this was back in March 2005, and I'm pleased to say that the Slony team seem to be improving things all the time. Once I'd got the dbmirror system working I did follow up on the postgres general mailing list and got some very useful pointers to both Slony documentation and very valid reasons why it is a better solution for some situations than DBmirror. It also became clear that in theory there is no reason why Whitebeam should not work with Slony-I and I fully intend to revisit this solution when I have some spare time! (if anyone gets there before me then please get in touch and share your experiences!) dbmirrorIt turns out that the standard Postgres distribution includes a perfectly adequate master to multiple slaves replication system - called 'dbmirror'. It's in the 'contrib/dbmirror' directory in the source tree. It wasn't perfect, but was very simple and worked. No messing! With a standard Whitebeam installation we carefully followed the dbmirror instructions to configure the database. The installation modified the database in the following ways:
So far so good. On a separate machine we then set up a mirror of the master database using db_dump and db_restore. We had to restore just the data - not the schema - and we didn't restore the dbmirror control tables, although there was no reason why we couldn't. dbmirror has to be started with both databases synchronised - it won't allow you to start with an empty slave and copy across the entire dataset, but then replication would be a very inefficient way of doing this for a large database. With everything installed we were ready to start replication. In dbmirror there are two parts to this:
The replication process in the standard dbmirror distribution is written as a Perl script (DBmirror.pl). You can run this on either the master, or the slave or a third machine as long as the hosting machine has Postgres connectivity to both the master and the slave databases. You can also run multiple instances of the script to replicate to multiple slaves or even to chain from master to slave to slave. It's a very flexible and powerful system. With everything in place and the replication script we started making changes to the master database. Replication worked a dream - we watched as changes to the master magically appeared on the slave. dbmirror performanceWhitebeam uses the Postgres database for all storage, including things like files and large serialised JavaScript objects. While DBmirror.pl coped admirably well with the small changes, we noticed performance on larger data fields getting very slow. Replication a 100Kbyte file object stored in a BYTEA field took 10 mintures and places a very heavy load on the processor.. We were obviously very concerned about this - it made what we'd initially thought to be a superb replication system into one that we were not confident of deploying in a high performance environment. Investigating the Perl script showed a number of potential inefficiencies, although we felt that whatever we did would not significantly enhance performance. We needed an alternative. Replacing DBmirror.plWorking through the logic in DBmirror.pl showed us how the replication was being handled. We also had some concerns about the behaviour of the script if the slave database were to be temporarily unavailable - probably requiring the scripts to be restarted. Taking the core logic of DBmirror.pl, we decided to create a high speed C++ implementation, and at the same time address a number of the reliability issues. This code has now been released as part of Whitebeam. The new C++ implementation works in a very similar way to the Perl version, reading a configuration file to define master and slave. The speed of replication of very large objects is now acceptable. Replicating a file insert of a 250K file now takes less than a 500ms on our test machines, which is more than adequate. 'replicate' executableThe C++ replication engine is available within the Whitebeam source tree at the moment. It is however entirely generic and should work in any online environment that DBmirror.pl works with. The only thing we haven't looked at is the redirection of SQL changes to files which the Perl implementation supports. Right now the code is a single C++ source file, but makes use of some of the basic Utility classes in Whitebeam (due to time-contraints!) It could be decoupled with a little effort. Once built however the binary has no dependancies on the rest of Whitebeam. Want to know more?'replicate' has been written by Peter Wilson, Whitebeam architect, at YellowHawk Ltd. and contributed to the Whitebeam source tree released under GPL. You can contact the author via his web site. |