XML Processing using the Whitebeam Environment
SubjectThe 'Whitebeam' programming environment is built around XML - central to the environment is a sophisticated XML parsing engine. This engine is integrated into the Whitebeam Apache module and accessible through the JavaScript environment. This paper describes in detail this environment and how it can be used. The paper is fairly long and tries to be both an overview of the technology and a complete guide to the XML aspects of the system. The paper is broken into the following sections:
OverviewThe Whitebeam system contains a powerful and flexible XML parser. The features of the parser - and the reprsentation of XML documents processed by the parser - are visible within the Whitebeam project as a set of JavaScript classes:
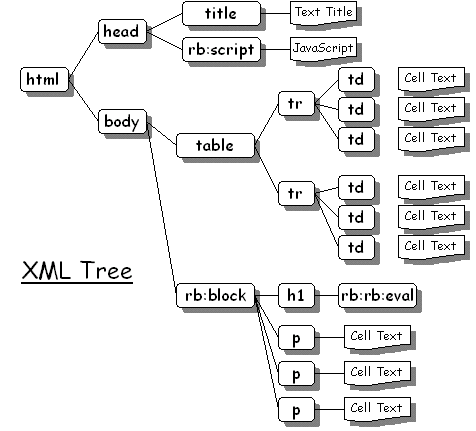
Together the classes allow an XML parser to be create - an XML tree to be constructed from a document, that tree be represented by a collection of specialised JavaScript files. The simplest way to understand the basics of the environment is to look at a simple example: To understand what is happening now requires an overview of how Whitebeam processes XML data to build - and make available an XML tree. This is the subject of this tutorial! How XML data is processed.Before you can understand the XML tree structure in Whitebeam you need to understand a little about how the Presentation Engine puts pages together. Page generation is a two stage process:
Stage 1: Buiding the XML Tree.Stage one builds the tree. The resulting tree is represented in the following diagram: This generates an internal representation of the tree. This is done internally for the main Presentation Page, and is performed manually by calling XmlParser.build Each of the nodes within the tree has some associated behaviour that has yet to be executed, this behaviour is determined by the name of the tag. (Generally the behaviour of a tag when it is executed is to generate its output representation that will be sent to the browser. How it does this is down to that specific tag). Stage 2: Executing the XML Tree.Each element in the XML tree (XML tag, text, comment etc) has an 'output' area associated with it. In general the intention is for each element to set its output area to be the text it wants to send to the client. For example for a simple text element the default behaviour is to set the text element's output area to be the same as the text it contains. In order to get the elements to populate their output areas the tree (or a sub-part of the tree) must be executed. The Presentation Engine does this for each Presentation Page - taking the root of the tree and getting it to execute itself. For trees constructed using the JavaScript API you can manually execute a portion of the tree by invoking the 'execute' method. Separating the tree build from executing the XML allows a branch of the tree to be executed more than once if necessary - potentially creating different output each time. This is how things like the rb:repeatfor tag is executed - the block of XML withing the rb:repeatfor tag is executed a number of times with loop variables changing each time. Whether or not the text gets eventually output depends on what the node'sparent wants to do. This behaviour is either defined 1) as default behaviour by the Whitebeam system or 2) the default behaviour can be overridden by the developer by using the <rb:macrotag> facility or 3) a user defined tag can have its behaviour specified by the developer by using the <rb:macrotag> facility or - finally - 4) by explicitly manipulating the XML tree using the JavaScript API. A simple HTML tag like the paragraph marker <p> will generate its output by executing each of its children and then concatenating the output from each of those into its own output area. Consider the following example:
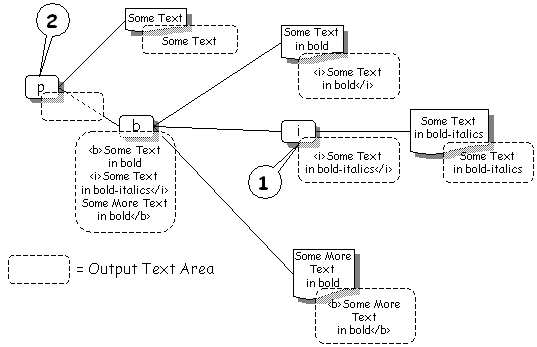
The paragraph tag is in the process of being processed. It's behaviour is to execute each of its children. The child XML tags in this example are all standard XHTML mark-up. The behaviour of these tags it to recursively process their children then concatenate their output along with their own wrapper. Conside the <i> tag (marked [1] in the diagram). This has executed its child - a simple text element. The output area of the text element has been set to the contents of the text field : "Some Text in bold-italics". The <i> tag then sets it's output area to be the concatenation of all it's children - wrapped in <i> and </i>. This happens all the way up the tree. The diagram illustrates the contents of the output areas for each XML element after all the children of the paragraph [2] have been executed but before the paragraph has generated its own output. You can see that to generate the contents of its own text area the paragraph element simply concatenates the contents of its own direct children - wrapping them in a <p> and </p> . JavaScript APIThe XML tree is mapped into the JavaScript environment as a hierarchy of JavaScript objects. Full details of the API are documented here. This section provides a very simple overview. The core class is the XmlParser. An instance of this is used to build the Presentation Page itself - and is available as rb.xml. So - for example - you can find the root of the Presentation Page XML tree as rb.xml.root - which is an instance of XmlTag. You can create your own parser in JavaScript and then use that parser to build an XML tree from a source XML document. Example: Once the tree has been built - you can execute it - or investigate the basic structure. Usually you would execute the tree once - but at times you would execute a subtree - say that satisfies some specific request such as displaying a section of a document. The XmlTag class is the most important to the structure of the document - since it basically is responsible for building that structure! The class itself has a set of named properties and a set of numbered properties. The numbered properties allw the object to be treated as a numeric array - each numeric subscript is a child XML element ofthe tag. So - conside the following simple XML document: If this is compiled with aParser then 'aParser.root' is a virtual XmlTag - it is NOT one of the elements in the document. Instead it is an un-named tag that contains as it's children the contents of the document. So in this example aParser.root[0] will be the <html> tag. The structure is recursive and so aParser.root[0][0] is the <head> tag, aParser.root[0][1] is the body tag. The Whitebeam environment provides several powerful mechanism for searching the XML tree to find sub-trees of interest. The simples is to simply search for an element with a specific tag-name. For example: Will return a JavaScript array of all the tags with this name 'body'. In this example this will yield an array with a single element - the body tag from the sample document. Whitebeam also allows much more sophisticated searching using the XPath query mechanism as defined by the W3C. This allows both the searching and extraction of data from the tree. So for a simple example - conside the following query: Will return all XML tags with an align attribute - the value of which is 'left'. Again - in this example this will return a set of nodes comprising the simgle matching element in the document. Note that the xpath method represents sets of XML elements as a instance of an XmlNodeSet class. XmlNodeSets are specialisations of the basic JavaScript Array - with the added benefit that yo can do do XPath queries on the result. See the separate XPath tutorial for more information. Special Behaviour.The behaviour described above is the default behaviour for a standard XML/HTML formatting tag. Many of the Whitebeam tags generate their output in different ways. It is important to realise that how a tag generates its output - and how it makes use of any of its children is entirely at the discretion of that element. The following is a brief description of how a couple of special Whitebeam XML markup generate their output.
The 'rb:block' tag is a very good example of how tags choose to execute - or not - their children. In the case of the block tag - its implemetation is to not execute those children. So, what is the point of it? See below... Manually Executing XML SubtreesThe XML tree built with the XmlParser.build is generally 'executed' in order to populate the 'output' area of each element. It is not 'required' that you execute the XML - there are applications that may just require the basic structure of the tree. At any time the output area may contain different things:
You can see from the description of the rb:block tag above that initially the output areas of all children of the block will be empty. In JavaScript you can however get hold of the sub-tree of the rb:block tag and execute it. To do this give the block tag an id (using the rb:id attribute). This is illustrated below: This example block is labeled - so we can find it - it has an 'id' and so we can simply search for the element with the XmlTag.findId method on the root of the tree. eg: Remember at this stage these tags have never been executed! If you now call 'var text=tag.bodytext()' the result will be an empty string. To generate output you have to first execute the tag. Do this using the tag.execute() method. The normal behaviour of this method is to run the tag on which it is invoked. An exception occurs where the tag is an 'rb:block' tag - because the effect of that tags execute is to do nothing! In the case of an rb:block tag all of the children of the tag are executed. This will effectively populate the output areas of each of the children. Note that in the example above the block contains active server-side behaviour in the form of <rb:eval...> tags. The block can be used in a loop to dump the contents of an object's properties:
Implementing XML Macros (rb:macrotag)The tag processing can be used extensively in implementing your own specialised tags - or in providing translations from one XML format to another. In this case the macro itself is defined using the rb:macrotag tag. This declares a new tag, the name being defined by the 'name' attribute of that tag. If the 'name' attribute of the macrotag is the same as an existing, default tag (such as 'body'), the Presentation Engine will execute the behaviour defined by the macro instead of the default behaviour. The Presentation Engine implementation of the rb:macrotag tag creates an internal representation of the named tag and then stores the JavaScript implementation against that tag. When the engine subsequently finds an instance of the new tag in the document it calls the JavaScript implementation for that tag. The implementation can use the JavaScript XML modelling rb.xml.thisTag method to access the XML body of the tag. As with the rb:block example, the engine does NOT automatically execute the body of the macro - to do so would reduce the scope of the JavaScript implementation. So to get the body text of the tree your must first execute the tree using tag.execute(). This does of course give the JavaScript implementation of the tag the freedom to only execute a portion of the body tags. Consider an example implementation of a tag called '<switch...>' that we want to provide. This will take a number of child tags - <case...>. We'd use this as follows: This is similar to the JavaScript 'switch' statement - but executed in tags. This illustrates why the Presentation Engine does not automatically execute trees under macro implementations or block tags. The implementation of <switch...> will search through the list of provided cases and only execute the one that matches the result code. This means that only one of the redirection tags will be executed. A more complete example of how to use tag.execute and the rb:macrotag tags can be found in the Whitebeam examples. ExampleThe following simple example shows a JavaScript recursive function that gets the tag tree for the XML tag called 'root' (a dummy table) and then provides a summary of the tree in the web page output. |