

Whitebeam Architecture
Whitebeam is a an object orientated, XML-centred web application server. In a number of ways it can be compared with environments such as PHP, ASP and JSP. Like these environments Whitebeam accepts requests for web-pages and in response reads files that contain both HTML and embedded programme logic, processes these files and returns the processed version of the file to the clients browser. Unlike most other environments, Whitebeam follows a processing model similar to client-side browsers by processing the source files as XML, building an XML parse tree then processes that tree. Within the tree each tag can have specific behaviour, either defined by the environment or by the application programmer using JavaScript. Design aimsWhitebeam has been designed from the ground up to meet some fundamental requirements, and architected as an overall system with these objectives in mind:
Whitebeam architectural modelWhitebeam addresses these design aims by breaking the web-application system down into a number of functional elements and allowing those elements to be connected over standard communications protocols. This in turn allows those elements to either run on the same server for small installations or on separate servers for larger environments. Today this scheme is generally refered to as an XML services model, although Whitebeam pre-dates a number of these ideas. Figure 1 illustrates how these elements can be used to build a scaleable, resilient, secure environment. 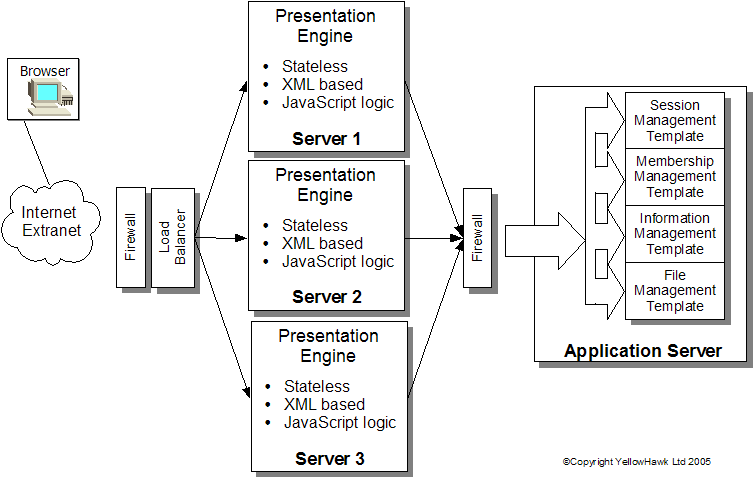 Figure 1 : Whitebeam physical architecture There are two distinct elements to a Whitebeam system : a front-end processor called the 'Presentation Engine'; a set of 'backend' application logic blocks called templates. Presentation EngineThe Presentation Engine is an Apache module - as of version 0.9.35 this will work in either Apache 1.3.x or Apache 2.x. The key with the Presentation Engine is that it is entirely stateless - it remembers nothing between generating pages. Anything that might require state to be stored is offloaded to a 'template' that can run on a separate server.>/p> A stateless presentation engine gives immediate scaleability to the entire system. Dynamically generating web pages is generally a CPU intensive activity - with the bulk of the CPU takeen up process text files, extracting embedded scripts and executing them. By making the logic that does this processing stateless you are free to run the same software on multiple servers and place a load-balancer in front of them. What's more a stateless Presentation Engine doesn't store any critical information. This means that not only can you have lots of them, they can use inexpensive hardware. There is no need for RAID array hard disks, dual networking card etc. You can build an array of inexpensive 'Front-end processors' running the Presentation Engine and use a load-balancer to automatically monitor for and switch out failing devices. Storing data (templates)Of course the data does have to be stored somewhere, which is where the back-end 'templates' come in. The Presentation Engine interracts with templates through an XML based communication protocol. It's very similar to XML/RPC. The protocol supports the encapsulation of procedure calls between the presentation engine and the templates (and in theory between templates, but we've never used that faacility). A simple example. Most web development environments have a method of 'session management'. This overcomes the architectural limitation in the web that has no concept of a session and makes every page stateless. A single-server centric environment such as PHP provides a set of routines for handling sessions. The session_XXXX functions. Because of the nature of PHP these sessions are stored in files, which are stored (by default) as files in the /tmp. directory. This works fine for a single server solution, but write an application using this interface and find you can't get a fast enough server you have problems. The 'state' for a session is contained on a single server. You'd normally then have to go back over your application and re-write the session logic, which tends to appear in most pages. By separating the session logic into a 'template' Whitebeam avoids this problem. In a single server solution the session template runs on the same box as the Presentation engine. Need more power though and you can simple add a second server and make it talk the the session template on the first server and you've doubled your front-end processing power. Why 'templates'? What's different?We've taken the approach in Whitebeam of adding significant complex generic functionality into the templates. They are not simply a very thin vaneer around another application. This reduces the learning curve before you can write an application, and also aids security. As an example one template (catalogue) encapsulates a hierarchical data repository which is modelled in a set of database tables. The interface to the catalogue comprises simple JavaScript method calls. Behind the scenes the template abstracts all the complexity of searching sub-trees in SQL away from the user. JavaScript makes data storage easy through object serialisation, so the application developer doesn't need to design a database schema for every application. The original design of the templates has been remarkably flexible. The 'catalogue' template just mentioned has been used to build obvious applications like libraries and product catalogues. It has also been used for more abstract concepts such as threaded message boards, work-flows, job queues and content management systems. One other benefit of the template model for database access is that it allows us to share a single database instance to store data for hundreds of web-applications simultaneously. The template implements the secure access to the data owned by each specific application. This cuts down on database management time and data complexity. Beyond templatesOf course, no matter how good we were at deciding the functionality we put into the original templates, there are occassions when you need to go further. Either because the data being represented is so far removed from the capabilities of the existing templates, or because modelling within the template framcework would become un-necessarily convoluted. The application developer has two options at this point:
Writing a new template is fairly straightforward. Whitebeam comes with a compiler that can take an XML service interface definition and build skeleton C++ files ready to be compiled. The native Postgres interface allows the application to interface directly with the database server. Note that the flexible model of Whitebeam allows any standard templates and bespoke functionality. SummaryFigure 2 summarises the various components of a Whitebeam system as discussed in this document. 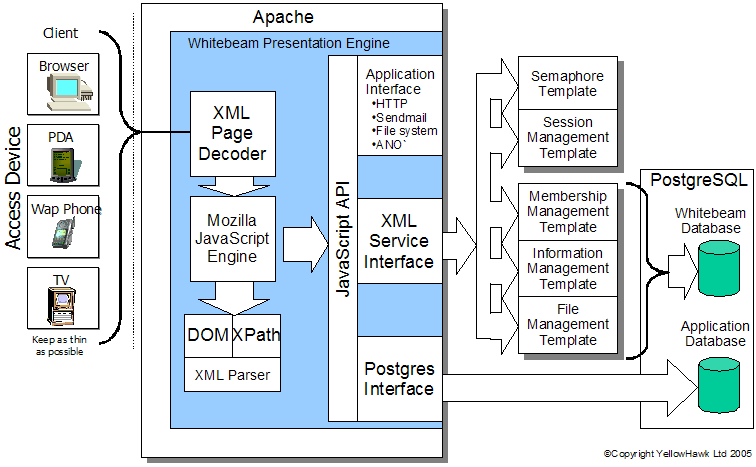 Figure 2 : Architecture details Looking into the 'Presentation Engine'The Presentation Engine builds output to be sent to client browsers. It's similar to PHP, ASP and JSP in that it's normal mode of operation to service a request to to load some source files that contain instructions for that page. These files are fed into a translation processor that generates output that is returned the tlhe client. This is illustrated in figure 3. 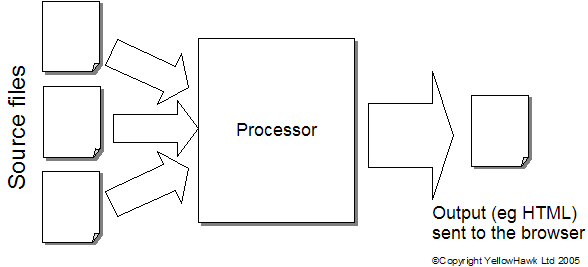 Figure 3 : Black box web engine The processor generates output by applying a set of rules. The rules that are applied is one of the main differences between Whitebeam and other purely text processing systems. Most systems, such as PHP, take a source files and simply search for substituion elements buried within the text. In the case of PHP the markers include <?php and ?> (there are others!). Whenever PHP sees these markers it expects the text between them to be PHP script ('C' like scripting language). It takes this text and runs it through an interpreter for that language, replacing the whole of the markers and text from the input stream with the output from the script in the input stream. PHP has no concept of the contents of the file other than that it is text with embedded markers. 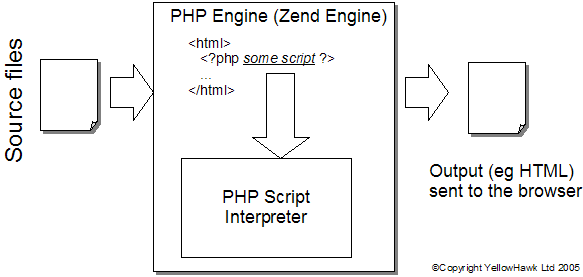 Figure 4 : PHP processing model If you contrast this with a typical browser model, which can also include script, there is a marked difference, and with that a very powerful tool. A web-brower processes HTML files that have enbedded script tags. Most server-side technologies process text files that include script. Sound like a minor point? Browsers understand HTML (and XML)) and will process files in two stages:
The behaviour of some tags means that they happen to include script which can be extracted and run through a script processor. Because the XML tree has been generated this gives the script that does exist some very powerful features to manipulate that tree. In browesrs this interface has been standardised as the 'Document Object Model'. It allows script to search the tree, modify the tree, copy portions of the tree. It's probably the single most powerful scripting resource on the browser. Most server side technologies don't have this ability - all they can do is generate text output to replace text input text. Nothing more. With Whitebeam we took the same approach as the browser. We expect all the source files for an application to contain valid XML/HTML. The first thing the Presentation Engine does is to build a data structure representing that tree and then execute each tag by walking that tree. This is illustrated in figure 5. 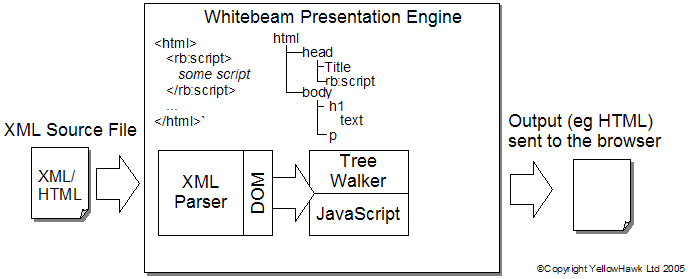 Figure 5 : Whitebeam XML Engine Whitebeam builds an XML tree representation of the source file and then walks each of the nodes in that tree to generate output. Each tag can have different behaviour. The default of course is simply to execute it's children then copy the combined output to the browser. The ability to have different behaviour for different tags is very powerful. <rb:script> is very much like the client-side <script> tag - it interprets the body as JavaScript and presents it to the Mozilla JavaScript engine. Other tags haowever are less obvious - the standard HTML <form> tag has behaviour that allows Whitebeam to automatically insert session identification into form requests. <rb:repeatfor> allows a block of XML it be repeated a number of times (say, rows in a table) The 'tag library' model is also extensible - allowing application developers to create bespoke behaviour for tags within the tree - the behaviour being defined in JavaScript. We call these 'macro tags'. This is much cleaner than the mess of script often found in many server-side applications. The existence of a DOM allows JavaScript to search for XML elements, repeat elements (for example within loops). The XML model and the server-side DOM add a whole extra dimension to server-side application development. SummaryHopefully you've found this overview useful and that you can start to appreciate the power of Whitebeam and the ways in which it differs from other server-side technologies. You'll find a lot more information on the site covering the details of the various components including full API information. If you can't find what you want then please make use of the SourceForge discussion forums. |