
| Site Map | |
| Home | |
| Application Guide | |
| Reference | |
| Community | |
| Contact Whitebeam | |
| To-Do | |
| Download | |
| Credits | |
| Licence | |
| Whitebeam Users | |
 |
|
JavaScript XML Tag Object
JavaScript XmlTag Object |
XmlTag Object | If the body element is another XML tag then the this is represented by an instance of the XmlTag class. You can see how this can be extended to contain any level of hierarchy of XML tags. |
String | If the body element is text then the matching array element will be a simple JavaScript string. |
 | The tag tree generated by rb.page.tagtree only includes representations of XML tags and text elements. It will NOT include representations of XML comments or XML declarations (basically anything starting with '<!'). Also the current version of the parser does not support processing instructions (basically anything starting with '<?'), if it encounters them an error will be generated. |
How XML data is processed.
Before you can understand the tag tree that has been generated you need to understand a little about how the presentation engine puts pages together. Page generation is a two stage process:
Parse the XML source and generate a tag tree.
Execute each of the nodes in the tag tree to generate output.
Stage 1: Executing the XML Tree.
Stage one builds the tree. The resulting tree is represented in the following diagram: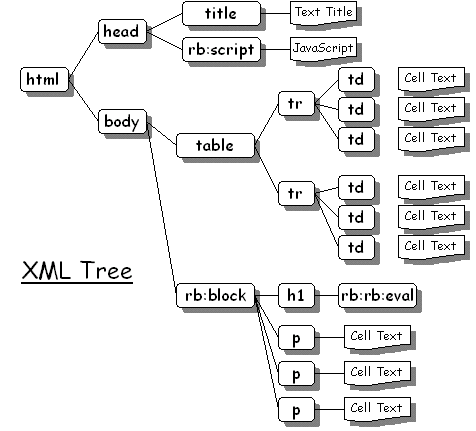
This generates an internal representation of the tree. Each of the nodes within the tree has some associated behaviour that has yet to be executed, this behaviour is determined by the name of the tag. (Generally the behaviour of a tag when it is executed is to generate its output representation that will be sent to the browser. How it does this is down to that specific tag).
Stage 2: Executing the XML Tree.
The presentation engine takes the root of the XML tag tree and executes it in order to generate the page it will ultimately send to the browser. Each node (XML tag, text, comment etc) has an 'output' area associated with it. In general the intention is for each node to set its output area to be the text it wants to send to the browser. For example for a simple text element the default behaviour is to set the text element's output area to be the same as the text it contains.
Whether or not the text gets eventually output depends on what the node'sparent wants to do. This behaviour is either defined 1) as default behaviour by the Whitebeam system or 2) the default behaviour can be overridden by the developer by using the <rb:macrotag> facility or 3) a user defined tag can have its behaviour specified by the developer by using the <rb:macrotag> facility.
A simple HTML tag like the paragraph marker <p> will generate its output by executing each of its children and then concatenating the output from each of those into its own output area.
Consider the following example:
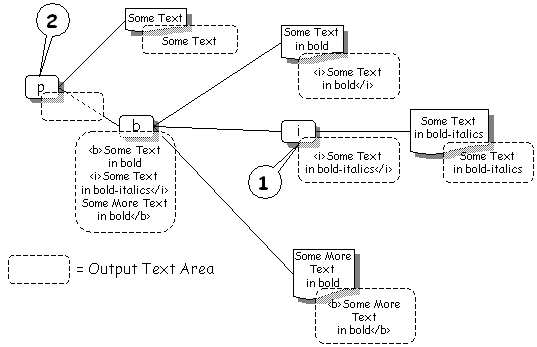
The paragraph tag is in the process of being processed. It's behaviour is to execute each of its children. The child XML tags in this example are all standard XHTML mark-up. The behaviour of these tags it to recursively process their children then concatenate their output along with their own wrapper. Conside the <i> tag (marked [1] in the diagram). This has executed its child - a simple text element. The output area of the text element has been set to the contents of the text field : "Some Text in bold-italics". The <i> tag then sets it's output area to be the concatenation of all it's children - wrapped in <i> and </i>.
This happens all the way up the tree. The diagram illustrates the contents of the output areas for each XML element after all the children of the paragraph [2] have been executed but before the paragraph has generated its own output.
You can see that to generate the contents of its own text area the paragraph element simply concatenates the contents of its own direct children - wrapping them in a <p> and </p> .
Special Behaviour.
The behaviour described above is the default behaviour for a standard HTML formatting tag. Many of the Whitebeam tags generate their output in different ways. It is important to realise that how a tag generates its output - and how it makes use of any of its children is entirely at the discretion of that element.
The following is a brief description of how a couple of special Whitebeam tags generate their output.
| Tag Name | Behaviour |
|---|---|
| rb:block | An rb:block tags execution behaviour is to do nothing. It does
not execute any of its children and so the children will not put
anything into their output areas. |
| rb:macrotag | An rb:macrotag tag does not generate any output. The effect of executing a macrotag is to record the new tag as being defined (or an existing tag as being overridden). The JavaScript contained within the macrotag is used to implement that tag when it is seen elsewhere in the document. |
The 'rb:block' tag is a very good example of how tags choose to execute - or not - their children. In the case of the block tag - its implemetation is to not execute those children. So, what is the point of it? See below...
Manually Executing XML Subtrees
The XmlTag class represents a portion of the XML document tree - as returned from rb.page.tagtree. The text() and bodytext() methods of XmlTag access the output area of the tag. But at any time the output area may contain different things:
If the tag has yet to be executed the output area will be empty.
If it has been executed then it will contain the contents from that execution.
A tag tree can be executed multiple times in order to produce different output. At any time the 'output' area of an element contains the text from the last execution of that element.
You can see from the description of the rb:block tag above that initially the output areas of all children of the block will be empty. In JavaScript you can however get hold of the sub-tree of the rb:block tag and execute it. To do this give the block tag an id (using the rb:id attribute). This is illustrated below:
<rb:block rb:id="myBlock">
<tr>
<td>
<rb:eval expr="prop">
</td>
<td>
<rb:eval expr="object[prop]">
</td>
</tr>
</rb:block>
This example block is labeled - so we can find it - with the name "myBlock". Note that thie block contains the necessary HTML for a single row in a table. We can now get this code subsequently in an <'rb:script...> tag using the rb.page.tagtree method and specifying 'myBlock'.
<rb:script>
var tag = rb.page.tagtree("myBlock")
</rb:script>
Remember at this stage these tags have never been executed! If you now call 'var text=tag.bodytext()' the result will be an empty string. To generate output you have to first execute the tag. Do this using the tag.regenerate() method. The normal behaviour of this method is to run the tag on which it is invoked. An exception occurs where the tag is an 'rb:block' tag - because the effect of that tags execute is to do nothing! In the case of an rb:block tag all of the children of the tag are executed. This will effectively populate the output areas of each of the children. Note that in the example above the block contains active server-side behaviour in the form of <rb:eval...> tags. The block can be used in a loop to dump the contents of an object's properties:
<rb:script>
var object = new Object;
object.name = "Peter";
object.sname = "Wilson";
var prop, testObj;
var tag = rb.page.tagtree("myBlock")
rb.page.write('<table border="1">');
for (var prop in object) {
// generate new output for this row.
tag.regenerate();
// Now output to the client (adds to my output area).rb.page.write(tag.bodytext());
}
rb.page.write('</table>');
</rb:script>
Implementing XML Macros (rb:macrotag)
The tag processing can be used extensively in implementing your own specialised tags - or in providing translations from one XML format to another. In this case the macro itself is defined using the rb:macrotag tag. This declares a new tag, the name being defined by the 'name' attribute of that tag. If the 'name' attribute of the macrotag is the same as an existing, default tag (such as 'body'), the Presentation Engine will execute the behaviour defined by the macro instead of the default behaviour.
The Presentation Engine implementation of the rb:macrotag tag creates an internal representation of the named tag and then stores the JavaScript implementation against that tag. When the engine subsequently finds an instance of the new tag in the document it calls the JavaScript implementation for that tag. The implementation can use the XmlTag classes and the rb.page.tagtree method to access the body of the tag. As with the rb:block example, the engine does NOT automatically execute the body of the macro - to do so would reduce the scope of the JavaScript implementation. So to get the body text of the tree your must first execute the tree using tag.regenerate().
This does of course give the JavaScript implementation of the tag the freedom to only execute a portion of the body tags. Consider an example implementation of a tag called '<switch...>' that we want to provide. This will take a number of child tags - <case...>. We'd use this as follows:
<switch expr="resultcode">
<case test="ok">
<rb:redirect src="nextpage.rhtm">
</case>
<case test="noresource">
<rb:redirect src="resourcepage.rhtm">
</case>
<case test="notfound">
<h1>Error - you specified a resource that does not exist.</h1>
</case>
</switch>
This is similar to the JavaScript 'switch' statement - but executed in tags. This illustrates why the Presentation Engine does not automatically execute trees under macro implementations or block tags. The implementation of <switch...> will search through the list of provided cases and only execute the one that matches the result code. This means that only one of the redirection tags will be executed.
A more complete example of how to use rb.page.tagtree and the rb:macrotag tags can be found in the Whitebeam examples.
Building an XML tree from source.
So far this paper has discussed manipulating parts of the XML tree of the current document, or of another document built into the current one using <rb:include...>. Another case to consider is where the application is given a set of XML source code and wants to manipulate the underlying XML structure. Possible examples are:
- XML data has been exported by a clients existing application - for example a catalogue of product, and the Presentation Page wants to extract data from that page to populate a Whitebeam template.
- Data from one XML application is to be translated (transformed) into another format for use by another application. For example an internal XML data structure is to be translated and displayed on a web browser.
The Presentation Engine allows 'on-the-fly' compilation of some XML source code using the rb.page.buildxml method. The method takes a string - assumed to contain XML - and parses it to build an XML tree. The resulting tree is then appended to the tag tree as a child of the currently executing child. Note that commonly, the currently executing child is an instance of the rb:script tag. A script tag usually contains exactly one child element - a text item - that contains the server-side JavaScript to be executed.
After executing rb.page.buildxml, the script tag will contain 'n+1' elements, where 'n' is the number of XML tags successfully extracted from the XML source. These elements will be indexed 1 through 'n'. This situation is illustrated in the diagram below. Note that running rb.page.buildxml is accumulative. In the diagram, if the string were executed again, the rb:script tag would acqiure two new XML child tags.
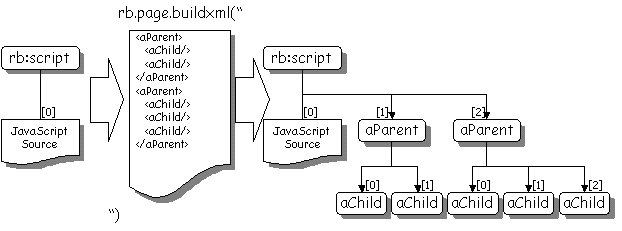
To manipulate the resulting XML tree the author must first find it and get a JavaScript representation of it. You find the tree by using the rb.page.tagtree method. Generally you will get the tag of the executing node then search its children for the appropriate node.
- The XML is parsed effectively using the same parser and parse rules as the XML page being executed. So the page will have all the HTML rules, will be case insensitive etc. as a normal XML page.
- The tag tree is constructed, but not executed! If you want to run the subtree using the Presentation Engine you need to get the XmlTag object that represents the tree using rb.page.tagtree, then invoke the regenerate method on that object.
- If you choose to regenerate the tree then the Presentation Engine executes all it's known handlers for each of the tags in the tree - just as it would for the original page. This provides a very powerful way of processing the XML data by defining rb:macrotag implementations for some of the key elements in the tag tree.
Example
The following simple example shows a JavaScript recursive function that gets the tag tree for the XML tag called 'root' (a dummy table) and then provides a summary of the tree in the web page output.
<html>
<head>
<title>Partners</title>
</head>
<table rb:id="root">
<tr>
<th>Head 1</th>
<th>Head 2</th>
<th>Head 3</th>
</tr>
<tr>
<td>row 1, col 1</td>
<td>row 1, col 2</td>
<td>row 1, col 3</td>
</tr>
</table>
<body bgcolor="#FFFFFF" leftmargin="0" topmargin="0" marginwidth="0"
marginheight="0" text="#000000" >
<H1>Decoding form parameters.</H1>
<h1 rb:id="HelloWorld">HEADER</h1>
<rb:script>
// define a function to dump one level of the XML tree.
function dumpTree(tag, spaces) {
var child;
rb.debug.write("<p>tag type:"+typeof tag+
" - "+tag.length+"</p>");
if (typeof tag == "object") {
// Its an object so dump its name then recursively
// display its children.
rb.page.write("--->"+spaces+"XML Tag:"+
tag.rb$tagname+"<br>");
for (child in tag) {
rb.debug.write("<p>Processing child object:"+
typeof tag[child]+"</p>");
dumpTree(tag[child], spaces+" ");
}
}
else {
rb.page.write("--->"+spaces+"Text,
length"+tag.length+"<br>");
}
}
var tag = rb.page.tagtree("root");
rb.page.write("<p>\n");
rb.page.write("<h1>Tag Tree Dump</H1><P>");
rb.page.write('<table border="1">\n');
dumpTree(tag,"tag");
rb.page.write('</table>\n');
rb.page.write("<h1>Tag Tree Dump Complete</H1><P>");
</rb:script>
</body>
</html>